La decisión de una correcta base de datos en tus proyectos no es algo trivial. De ello depende en el éxito de tus trabajos. El futuro del proyecto.
Los responsables TI nos enfrentamos a difíciles decisiones al comienzo del proyecto que marcan el devenir del resultado.
Existen diversos factores que voy a exponer en esta entrada…
La elección de un gestor de bases de datos, se está convirtiendo en algo crucial para la empresas. Tendremos que considerar el tipo, puesto que no todas ellas se basan en SQL.
Existen las bases de datos que no tienen que ser SQL y que representan un nicho importante en grandes empresas por sus ventajas.
Uno de los grandes retos es elegir un gestor que se adapte al volumen de datos a manejar y precio por el que estamos dispuestos a pagar. Obviamente, las bases de datos Open Source o de código abierto emergen como claras ganadoras en el plano económico, ahorrando sustanciales cantidades de dinero a compañías.
La elección de una base de datos debe ser estudiada detalladamente. Los gestores IT no pueden tomar dediciones equivocadas.
Mysql y PostgreSQL son dos populares alternativas en el mundo de las bases de datos abiertas. Pero no son las únicas y en muchos casos las mejores. El campo de bases de datos es ya maduro, y existen muchos productos eficaces en el mercado.
Consideraciones a tener en cuenta a la hora de seleccionar una base de datos.
- Precio. Evidentemente.
- Concurrencia, número de usuarios que son soportados por el gestor en un instante determinado. Desde unos pocos hasta millones.
- Tipo de datos a trabajar, no es lo mismo información en forma de registros, imágenes, películas, mapas, libros, objetos, etc.
- El volumen de los datos, cantidad de información. Desde Megas hasta Petabytes.
- Velocidad a la hora de realizar operaciones y transacciones. Velocidad a la hora de generar datos, de acceder a ellos o almacenarlos.
- La decisión sobre la importancia de las lecturas o escrituras.Pueden existir miles de usuario consultando información y pocos escribiendo.
- La necesidad de que la información se encuentre distribuida. En un sólo equipo o a través del planeta.
- Los mecanismos de acceso a la información por parte del motor. Si existen complejas consultas relacionadas. Si se va a realizar una minería de datos y un procesamiento analítico.
- Nivel de experiencia y aprendizaje de los ingenieros encargados de trabajar con el motor del gestor, mecanismos de consulta, habilidades en el lenguaje. Este requisito es fundamental puesto que para determinadas filosofías y metodologías de desarrollo, lo importante son las personas, y grado de conocimiento. Equipo de trabajo a tener en cuenta. Los gestores del motor y los encargados de manipular y consultar la información.
- El lenguaje de acceso empleado para manipular la información. Desde C hasta Golang o Python
- Grado de monitorización del gestor.
- El soporte ofrecido por el equipo de desarrollo del motor. Muy importante. Las actualizaciones del producto y mejoras. Elegir un gestor con futuro.
- Mecanismos de recuperación de la información en caso de pérdida de datos.
- Niveles de seguridad de acceso. Los datos son de uso común o nos encontramos con información de carácter personal o secreto.
- Niveles de integración con diversas tecnologías, para crear un ecosistema de convivencia entre diversos productos y versiones.
- Empleo. Si va a ser usada en la web, o en intranets locales. O diferentes delegaciones.
Por lo tanto un responsable TI necesita estudiar todos estos aspectos para escoger el gestor adecuado.
Últimas tendencias en el mundo de las bases de datos.
El State of the Art se dirige hacia el Big Data, la nube, los sistemas NoSQL, la alta disponibilidad, y adaptación a arquitecturas multiprocesador y dispositivos de estado sólido o (SSD)
Big Data: Un conjunto elevado de datos generalmente generado por dispositivos o devices. Ejemplos: datos sobre climatología, actividad de los usuarios en la web, tráfico, patrones de conducta social, información constante de procesos abiertos. Son datos abundantes y se incrementan de forma exponencial en el tiempo y con el uso. Una característica interesante del Big data es que los datos por si solos no poseen valor. Es decir, saber la temperatura que hace a las 4:30 de la mañana de un día cualquiera no es relevante, pero si analizamos todo en conjunto, la información, las medias, el resultado es información muy valiosa. El big data necesita pues gran cantidad de procesamiento y capacidades computacionales.
NoSQL
Los desarrolladores y proveedores de información requieren mayor flexibilidad a la hora de almacenar datos. Sus estructuras de datos son diversas. Estos sistemas difieren de los SGBDR, siendo lo más destacado la no utilización del lenguaje SQL para realizar consultas. Estos sistemas no garantizan el ACID (atomicidad, coherencia, aislamiento y durabilidad) y habitualmente escalan bien horizontalmente.
Los sistemas de bases de datos NoSQL crecieron con las principales compañías de Internet, como Google, Amazon, Twitter y Facebook. Estas tenían que enfrentarse a desafíos con el tratamiento de datos que las tradicionales RDBMS no solucionaban. Con el crecimiento de la web en tiempo real existía una necesidad de proporcionar información procesada a partir de grandes volúmenes de datos que tenían unas estructuras horizontales más o menos similares. Estas compañías se dieron cuenta que el rendimiento y sus propiedades de tiempo real eran más importantes que la coherencia, en la que las bases de datos relacionales tradicionales dedicaban una gran cantidad de tiempo de proceso.
En ese sentido, a menudo, las bases de datos NoSQL están altamente optimizadas para las operaciones recuperar y agregar, y normalmente no ofrecen mucho más que la funcionalidad de almacenar los registros (p.ej. almacenamiento clave-valor). La pérdida de flexibilidad en tiempo de ejecución, comparado con los sistemas SQL clásicos, se ve compensada por ganancias significativas en escalabilidad y rendimiento cuando se trata con ciertos modelos de datos.
Os dejo los enlaces de ejemplos de este sistema:

Dispositivos de estado sólido
La era de los discos duros mecánicos está llegando a su fin día a día. Los accesos al los dispositivos SSD a en cuanto a lectura y escritura poseen mayores virtudes. Las optimizaciones que se deben realizar para los accesos difieren de los discos duros tradicionales.
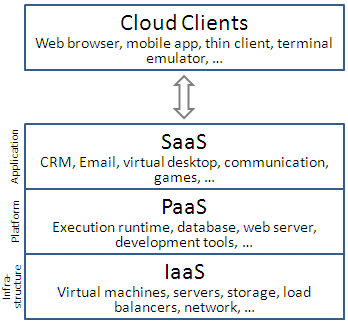
La nube (cloud)
Las empresas de internet despliegan sus propios sistemas de almacenamiento. Accediendo principalmente a archivos a través de la nube. Soportan principalmente múltiples sistemas operativos y optimizan de forma individual sus sistemas de búsqueda. Ejemplo Google Drive

Alta disponibilidad
Disponibilidad se refiere a la habilidad de la comunidad de usuarios para acceder al sistema, someter nuevos trabajos, actualizar o alterar trabajos existentes o recoger los resultados de trabajos previos. Si un usuario no puede acceder al sistema se dice que está no disponible. El término tiempo de inactividad (downtime) es usado para definir cuándo el sistema no está disponible. Por poner un ejemplo, Mysql presenta una alternativa especializada llamada MYSQL Clúster que permite asegurar alta redundancia y disponibilidad. Otro ejemplo es Clúster Oracle mediante RAC, que es la solución que Oracle presenta para que dos o más ordenadores llamados nodos puedan acceder a un solo repositorio de datos. SQl Server ofrece el reflejo de base de datos.
Más información : http://www.docstoc.com/docs/35935799/Soluciones-de-alta-disponibilidad-en-bases-de-datos
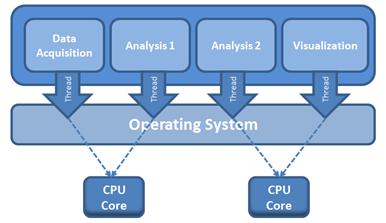
Sistemas con múltiple procesador
Procesadores multi-core: la tecnología de procesador se dirige hace tiempo a núcleos múltiples y procesamiento en paralelo. Las nuevas arquitecturas de software necesitan explotar la capacidad de computación. El procesamiento en paralelo se basa principalmente en Multiprocesadores fuertemente acoplados que cooperan para la realización de los procesos. El objetivo del paralelismo en lo sistemas de bases de datos suele ser asegurar que la ejecución del sistema se continuará realizándose a una velocidad aceptable, incluso en el caso de que aumente el tamaño de la base de datos o el número de transacciones. El núcleo de estos motores deben aprovechar al máximo los sistemas con múltiples procesadores.