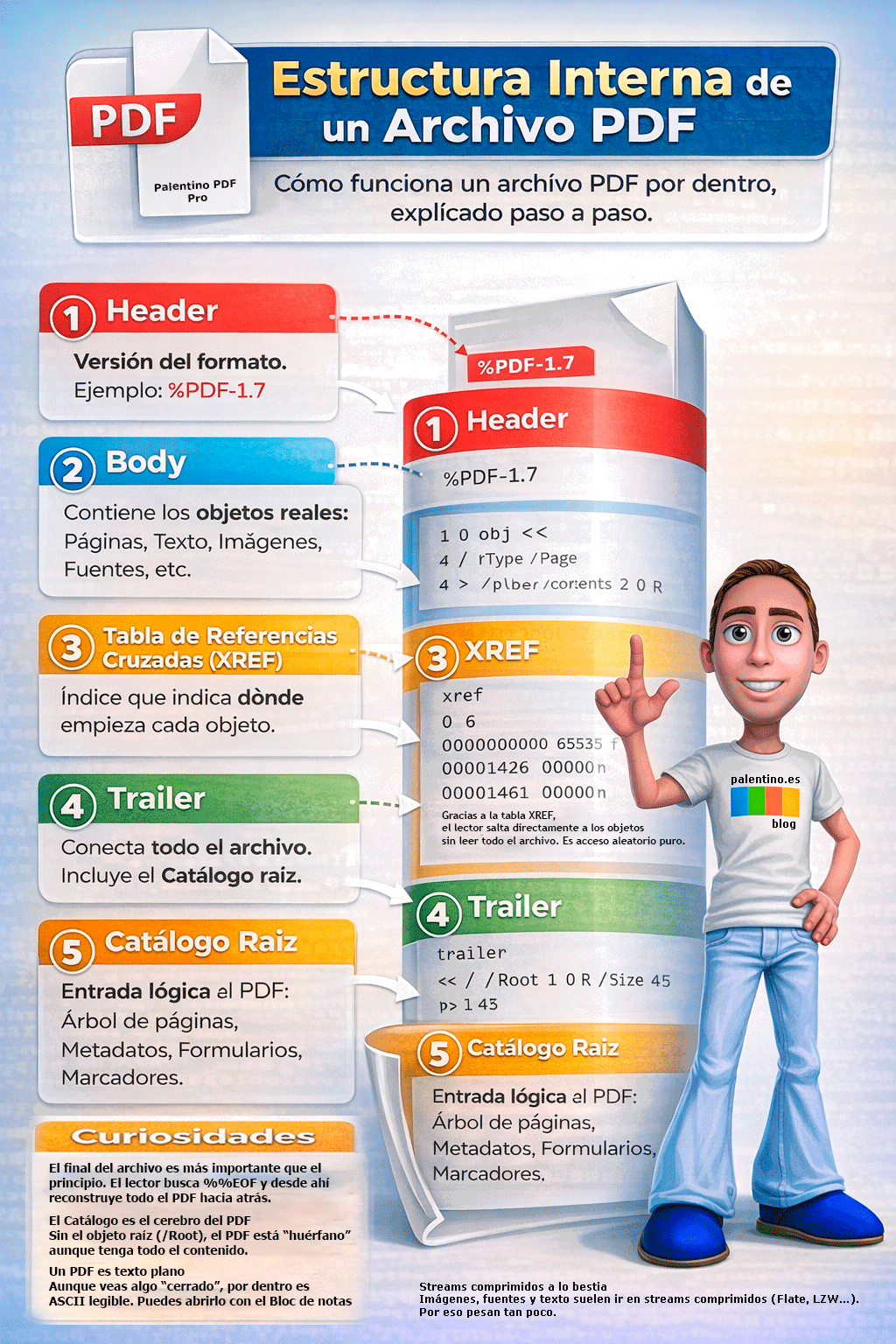
Un PDF no es solo un documento “cerrado”. Por dentro es una estructura ordenada de objetos, pensada para que cualquier visor pueda reconstruir exactamente lo que ves en pantalla.
Todo comienza con el Header, donde se indica la versión del formato (%PDF-1.7). A partir de ahí, el Body almacena los objetos reales: páginas, textos, imágenes y fuentes. No hay párrafos ni estilos como tal; el PDF funciona como un pequeño motor de dibujo que indica qué pintar y dónde.
Para localizar rápidamente cada objeto existe la tabla XREF, un índice interno que permite acceder al contenido sin leer todo el archivo. Gracias a esto, los PDF son rápidos incluso siendo grandes.
El Trailer conecta todas las piezas e indica cuál es el Catálogo raíz, el verdadero cerebro del PDF. Desde ese objeto se accede al árbol de páginas, metadatos, formularios y marcadores.
🔍 Curiosidades que sorprenden
- Un PDF es texto plano por dentro.
- Permite ediciones incrementales sin reescribirlo entero.
- Puede contener varias versiones internas.
- El orden visual no siempre coincide con el orden real.
- Puede ejecutar JavaScript (potente… y peligroso).
- El final del archivo (%%EOF) es clave para reconstruir todo.
Entender la estructura interna del PDF explica por qué a veces copiar texto falla, por qué pesan tan poco o por qué pueden ser un vector de malware. Un formato mucho más inteligente —y complejo— de lo que parece.