Cada vez que vas a descargar un modelo de IA local aparece lo mismo:
BF16, FP8, INT4…
Y la gran duda:
👉 ¿Esto lo podrá mover mi equipo o se va a quedar colgado?
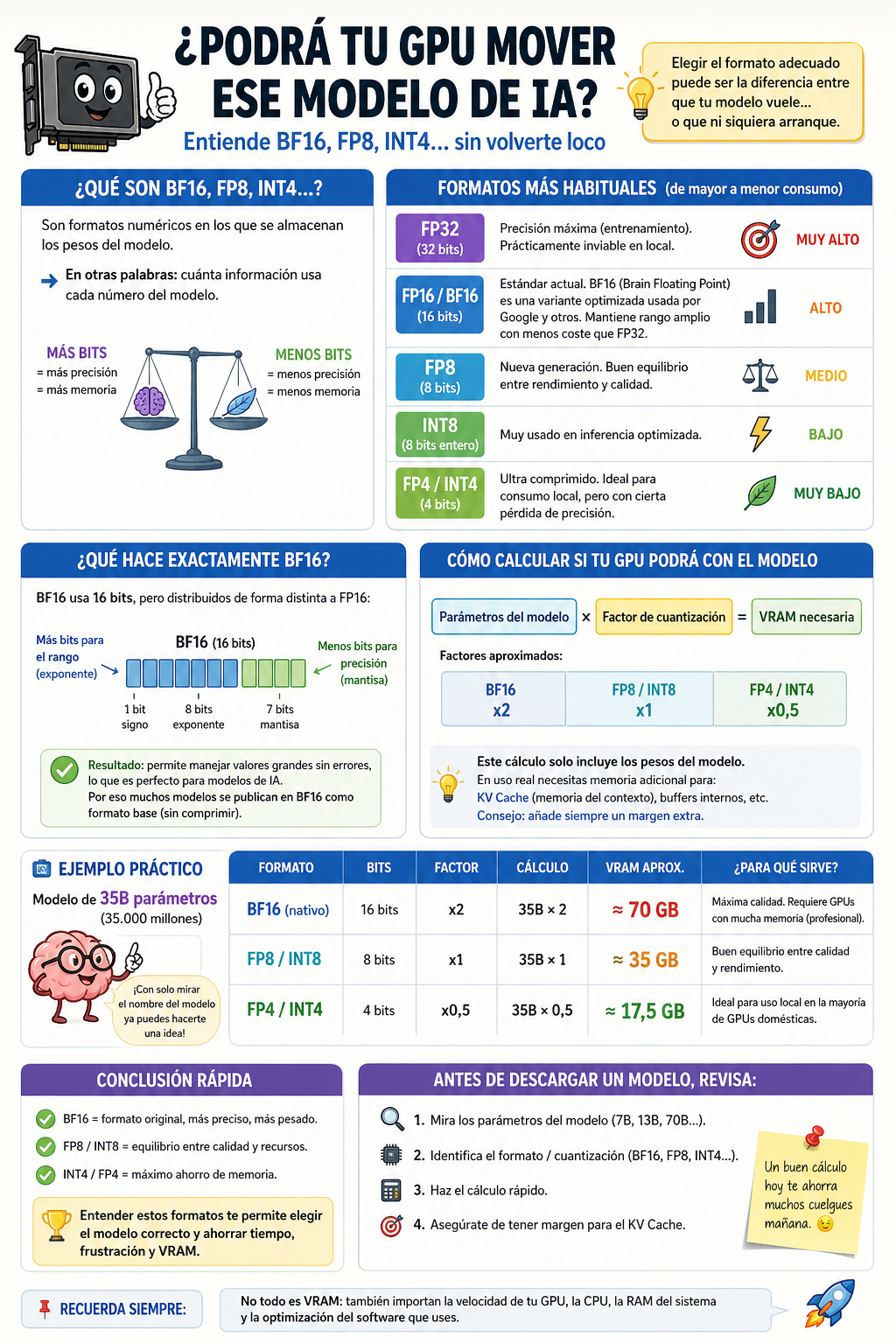
🔍 Primero: qué significan realmente esas siglas
Son formatos numéricos que definen cómo se almacenan los pesos del modelo.
👉 En simple:
cuánta información usa cada número
- Más bits → más precisión → más VRAM
- Menos bits → menos precisión → menos consumo
⚙️ Los formatos más comunes (de mayor a menor consumo)
- FP32 → máxima precisión (entrenamiento, inviable en local)
- FP16 / BF16 → estándar actual
- FP8 / INT8 → equilibrio
- FP4 / INT4 → ultra comprimido (ideal para local)
💡 ¿Qué es exactamente BF16?
BF16 (Brain Floating Point) usa 16 bits, pero optimizados:
✔ Mantiene un rango amplio de valores
✔ Reduce coste respecto a FP32
✔ Es el formato base en muchos modelos
👉 Por eso muchos modelos vienen en BF16 “sin comprimir”
⚡ El truco rápido que te ahorra tiempo
👉 Parámetros del modelo × factor ≈ VRAM necesaria
Factores aproximados:
- BF16 → x2
- FP8 / INT8 → x1
- FP4 / INT4 → x0,5
📊 Ejemplo real
Modelo de 35B parámetros:
- BF16 → ~70 GB
- FP8 → ~35 GB
- FP4 → ~17,5 GB
👉 Aquí ya ves por qué la cuantización es clave.
⚠️ Ojo (esto es lo que muchos olvidan)
Ese cálculo solo incluye los pesos del modelo.
En uso real necesitas más memoria para:
- KV Cache (memoria del contexto)
- buffers internos
👉 Consejo: añade margen o fallará / irá lento
🎯 Conclusión clara
- BF16 = más calidad, más consumo
- FP8 = equilibrio
- INT4 = máximo ahorro
👉 Entender esto te permite decidir en segundos si un modelo es viable en tu equipo.
💬 Si trabajas con IA en local, este cálculo te puede ahorrar horas de pruebas… y bastantes frustraciones.