










El Big Data no es algo nuevo, como concepto o término es usado ya desde hace una década. Cada vez somos más conscientes de la cantidad de datos que generamos, es por ello, que cada vez lo empleamos y mencionamos más.
“Data is the new oil”
de Clive Humby -2006
El señor Clive, expuso esa famosa frase hace tiempo.
Los datos son el Nuevo petróleo, los datos son dinero. Los datos son eternos.
Pero realmente si nos paramos a analizar este aforismo del Big Data, no es precisamente del todo cierto.
¿Y por qué no?
Primero porque el petróleo no es una fuente renovable, por el contrario, los datos no se acaban nunca, se crean constantemente, son eternos mientra existan sistemas. No son una fuente de recursos agotable. El crecimiento de información es exponencial,dia a dia. Hoy trabajamos con miles de exabytes de información. Por ejemplo, 5 exabytes es una cantidad tan grande, que podrían almacenarse todos los dialectos e idiomas empleados a lo largo de la historia de la humanidad.
Aunque la analogía principal de los datos con el petróleo, se refería al hecho de rentabilizar o ganar dinero fácilmente con la información, eso tampoco es realmente cierto, los datos para poder aprovecharlos, es necesario estructurarles antes de obtenerles, cómo y quien los va a analizar, donde los vamos a almacenar.
Una forma mejor de crear analogía al Big Data es tal y como define Jer Thorp en Harward Business Review:
“ Encontrar valor en los datos es mucho más un proceso de cultivar, que uno de extraer o refinar”.
Lo que hay que hacer es saber cómo estructurar los datos a largo plazo, en un entorno controlado, solamente estructurando bien los datos, obtendremos resultados.
Se tiende asociar Big Data a grandes datos, pero no solamente son grandes cantidades de datos.
No solamente son exabytes. Para que algo sea considerado big data, necesita cumplir una regla:
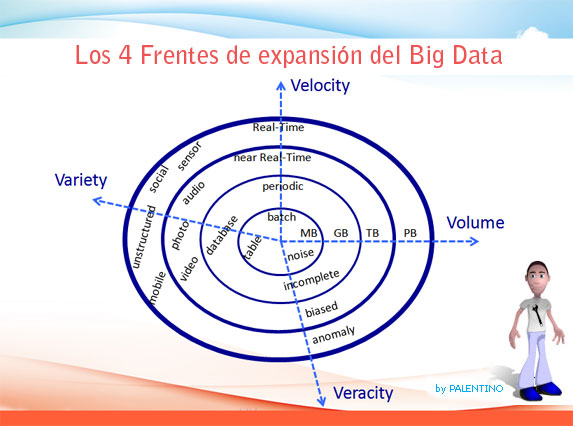
La regla de las cuatro V, o cuatro dimensiones del Big data, tal y como determinó en 2012 IBM.
Volumen (Volume).
Generamos datos cada segundo. Grandes cantidades
Velocidad (Velocity).
Generamos información rápidamente.
Variedad (Variety).
Los datos son diferentes en contextos distintos.
Veracidad (Veracity) – Ampliación de la ley original por parte de IBM.
Además es preciso que los datos sean correctos, ciertos. Es necesario desconfiar de lo que nos ofrece la información.
Para aquellos que no conozcan Hadoop, forma parte de una plataforma de código abierto para procesar big data. Pero un mito que realmente no es cierto es que Big Data significa Hadoop. Aunque Hadoop pueda hacer muchas cosas interesantes, existen otros productos.
http://es.wikipedia.org/wiki/Hadoop

Enlace oficial
Al igual que ocurre en muchas tecnologías, no podemos ser esclavos de un solo producto tecnológico. Puesto que el Big data es algo más que un producto conocido.
Muchos ingenieros en su día a día o transcurso profesional, comenten un error, casarse con una determinada tecnología. Se casan con frameworks, lenguajes, CMS, al igual que con Big Data.
“Casarse con un software es un pecado capital, gran error en un mundo en constante evolución y cambio.”
Software desarrollado por las compañías más grandes del mundo poseen sistemas que procesan el big data.
Pentaho está construyendo el futuro de análisis de negocios. Herramienta BI de software libre.
http://www.pentaho.com/
Netezza de IBM
http://en.wikipedia.org/wiki/Netezza
Vertica de HP
http://www.vertica.com/
Greenplum de EMC
http://en.wikipedia.org/wiki/Greenplum
DataFlux de SAS
http://www.dataflux.com/home.aspx?lang=es-es
Todas las grandes empresas quieren crear sistemas que procesen esta información.
“La clave esta en encontrar un software que se ajuste bien a las tecnologías”
Sepamos algo más …
Big Data (o grandes datos) en TI corresponde a una referencia a sistemas que manipulan grandes conjuntos de datos (o data sets). Las dificultades más generales en estos casos se centran en la captura, el almacenado, la búsqueda, compartición, el análisis, y visualización.
El límite superior de procesamiento se ha ido desplazando a lo largo de los años, de esta forma los límites que estaban fijados en 2008 rondaban los órdenes de petabytes a zettabytes de información.
Los científicos con cierta regularidad encuentran limitaciones debido a la gran cantidad de datos en ciertas áreas, tales como la meteorología, la genómica, la conectómica, las complejas simulaciones de procesos físicos, y las investigaciones relacionadas con los procesos biológicos y ambientales.
Las limitaciones también afectan a los motores de búsqueda en Internet, a los sistemas finanzas y a la informática de negocios.
Los data sets crecen en volumen debido en parte a la introducción de información ubicua procedente de los sensores inalámbricos y los dispositivos móviles del constante crecimiento de los históricos de aplicaciones (logs), cámaras (sistemas de teledetección), micrófonos, lectores de radio-frequency identification.
La capacidad para almacenar datos de la humanidad se ha doblado a un ritmo de cuarenta meses desde los años ochenta.En 2012 , cada día fueron creados cerca de 2,5 trillones de bytes de datos.
“Big data” ha incrementado la demanda de especialistas en gestión de la información y empresas como Software AG, Oracle Corporation, IBM, Microsoft, SAP, EMC y HP se han gastado más de 15 millones de dólares en proyectos de software que sólo se especializan en la gestión de datos y análisis. En 2010, este sector por sí solo valía más de 100 mil millones de dólares y está creciendo a casi el 10 por ciento al año: Aproximadamente el doble de rápido que el negocio del software en su conjunto
Las economías desarrolladas hacen uso cada vez mayor de las tecnologías de uso intensivo de datos. Hay 4,6 millones de suscripciones de teléfonos móviles en todo el mundo y hay entre mil millones y 2 billones de personas con acceso a Internet.
La Capacidad efectiva del mundo para el intercambio de información a través de redes de telecomunicaciones era 281 petabytes en 1986, 471 petabytes en 1993, 2,2 exabytes en 2000, 65 exabytes en 2007, y se prevé que la cantidad de tráfico que fluye a través de Internet alcanzará los 667 exabytes anuales para el año 2013.
En 2004, Google publicó un documento sobre un proceso llamado MapReduce que utiliza dicha arquitectura. El Framework MapReduce ofrece un modelo de programación paralela y la aplicación asociada para procesar gran cantidad de datos. Con MapReduce, las consultas se dividen y se distribuyen a través de los nodos paralelos y procesamiento en paralelo (El Map Step). Este framework tuvo un éxito increíble, y motivo a que otros quisieran copiar el algoritmo. Esto condujo a que, una implementación del framewok MapReduce fuese adoptado por un proyecto de código abierto de Apache llamado Hadoop, pero como desarrollaré más adelante no es el único.
Respecto a la tecnología
Big Data requiere tecnologías excepcionales para procesar eficientemente grandes cantidades de datos dentro de unos tiempos transcurridos que sean tolerables. Un informe de McKinsey (una de las mayores consultoras del mundo) en 2011 sugiere que las tecnologías adecuadas incluyen las pruebas A / B, de reglas de asociación de aprendizaje, clasificación, análisis de conglomerados, crowdsourcing, fusión de datos y la integración, el aprendizaje conjunto, los algoritmos genéticos, aprendizaje automático, procesamiento del lenguaje natural, redes neuronales, reconocimiento de patrones , detección de anomalías, modelos de predicción, regresión, análisis de los sentimientos, procesamiento de señales, supervisados y no supervisados aprendizaje, simulación, análisis de series temporales y la visualización.
Grandes volúmenes de datos multidimensionales también pueden ser representados como tensores, los cuales se pueden manejar de manera más eficiente mediante cálculo tensor, tales como el aprendizaje subespacio multilineal.
Las tecnologías adicionales que se aplican a grandes volúmenes de datos incluyen bases de datos masivos de procesamiento paralelo (MPP /Massively Parallel-Processing) , basado en búsquedas aplicaciones de minería de datos, redes de sistemas de archivos distribuidos, bases de datos distribuidas, la infraestructura basada en la nube (aplicaciones, almacenamiento y recursos informáticos) e Internet.
Algunas, pero no todas las bases de datos relacionales MPP tienen la capacidad de almacenar y gestionar petabytes de datos. Esto implícita la capacidad de cargar, controlar, copias de seguridad y optimizar el uso de las grandes tablas de datos en el RDBMS.
Los profesionales que emplean grandes procesos de análisis de datos son generalmente hostiles al almacenamiento compartido, más lento, prefiriendo el almacenamiento de conexión directa (DAS) en sus diversas formas de disco de estado sólido (SSD) a alta capacidad SATA dentro de los nodos de procesamiento en paralelo.
La percepción es que el almacenamiento compartido en arquitecturas SAN y NAS son relativamente lentas, complejas y costosas. Entrega de información real o casi en tiempo real es una de las características definitorias de análisis de Big Data. Por lo tanto, se evita la latencia cuando y donde sea posible. El costo de una SAN en la escala necesaria para las aplicaciones de análisis es mucho más alto que otras técnicas de almacenamiento.
Hay ventajas y desventajas para el almacenamiento compartido en el análisis de datos grandes, pero los profesionales del análisis a partir de 2011 no lo están muy a favor.
CRITICAS
Las críticas al paradigma de Big Data son de dos tipos, los que cuestionan las implicaciones del enfoque de sí mismo, y los que cuestionan la forma en que se hace actualmente.
“Un problema fundamental es que no sabemos mucho acerca de los micro-procesos empíricos subyacentes que conducen a la aparición de las redes Big Data”. En su crítica, Snijders, Matzat y Reips matizan que las suposiciones se hacen acerca de las propiedades matemáticas que no pueden en absoluto reflejar lo que realmente está sucediendo a nivel de micro-procesos.
Mark Graham se ha centrado en particular en la idea de que siempre se van a necesitar grandes volúmenes de datos para ser analizados en sus contextos sociales, económicos y políticos. A pesar de que las empresas invieren grandes sumas para obtener una visión de la información que entra por los proveedores y clientes, menos del 40% de los empleados tienen procesos y habilidades lo suficientemente maduros para hacerlo interpretarlos. Para superar este déficit de conocimiento, El big data debe ser complementada con “gran juicio”, según un artículo publicado en la Harvard Business Review.
En la misma línea, se ha señalado que las decisiones basadas en el análisis de grandes volúmenes de datos están inevitablemente basados en información del pasado, o, como mucho, la actual. Pero alimentados por un gran número de datos sobre experiencias pasadas, los algoritmos pueden predecir el desarrollo futuro si el futuro es similar al pasado.
En la Salud y la biología, los métodos científicos convencionales se basan en la experimentación. Para estos enfoques, el factor limitante son los datos relevantes que puedan confirmar o refutar la hipótesis inicial. Un nuevo postulado se acepta ahora en biociencias: La información proporcionada por los datos en grandes volúmenes sin hipótesis previa es complementaria y a veces necesario para los enfoques convencionales basados en la experimentación.
Defensores de la privacidad del consumidor están preocupados por la amenaza a la vida privada representada por el aumento de almacenamiento e integración de la información de identificación personal.
Danah Boyd ha expresado su preocupación por el uso de grandes volúmenes de datos en contentos privados descuidando la ciencia como la el objeto del estudio y muestra. Grupos de expertos han publicado varias recomendaciones a los políticos para proteger la vida privada y el derecho a la intimidad.
Respecto al Concepto de Minería de Datos
La minería de datos es un subcampo interdisciplinario de ciencias de la computación y se define comos el proceso de cálculo de descubrir patrones en grandes conjuntos de datos que involucra métodos en la intersección de la inteligencia artificial , aprendizaje automático , las estadísticas y los sistemas de bases de datos.
El objetivo general del proceso de minería de datos es extraer información de un conjunto de datos y transformarla en una estructura comprensible para su uso posterior.
El término es una palabra de moda , y con frecuencia es mal utilizado para referirse a cualquier tipo de datos a gran escala o de procesamiento de la información ( recogida , extracción , almacenamiento , análisis y estadísticas), pero también se generaliza a cualquier tipo de sistema de apoyo informático, incluyendo inteligencia artificial,aprendizaje automático y la inteligencia empresarial. En el uso de la palabra, la palabra clave es el descubrimiento, comúnmente definido como “detectar algo nuevo”.
La tarea real de la minería de datos es el análisis automático o semi-automático de grandes cantidades de datos para extraer interesantes patrones previamente desconocidos, tales como grupos de registros de datos ( análisis de conglomerados ), los registros de inusuales (detección de anomalías ) y dependencias ( minería de reglas de asociación ). Esto generalmente implica el uso de técnicas de bases de datos tales como índices espaciales .
Por ejemplo, el paso de la minería de datos puede identificar varios grupos en los datos, que luego se puede utilizar para obtener resultados de la predicción más precisa, en un sistema de soporte de decisiones.
La minería de datos utiliza la información de los datos del pasado para analizar el resultado de un problema o situación particular que pueda surgir. La minería de datos analiza los datos almacenados en gestores. Esos datos particulares pueden venir de todas partes del negocio, desde la producción hasta la gestión. Los gerentes también utilizan la minería de datos para decidir sobre las estrategias de comercialización de su producto. Se pueden utilizar los datos para comparar y contrastar entre los competidores. La minería de datos interpreta los datos en el análisis en tiempo real que puede ser utilizada para aumentar las ventas, la promoción de nuevos productos, o eliminar producto que no está de valor añadido a la empresa.
Anexo Herramientas para el análisis de datos BIG DATA
http://es.wikipedia.org/wiki/Hadoop
http://www.cloudera.com/content/cloudera/en/why-cloudera/hadoop-and-big-data.html
http://www.cloudera.com/content/cloudera/en/products/cdh/impala.html
http://en.wikipedia.org/wiki/MapReduce
Os dejo unos enlaces de herramientas empleadas para el análisis estadístico.
Herramientas de análisis estadístico.
Statistical Analysis tools:
- R language (http://www.r-project.org/)
- Matlab, http://es.wikipedia.org/wiki/MATLAB
- Octave, http://www.gnu.org/software/octave/, http://es.wikipedia.org/wiki/GNU_Octave
- SAS, http://www.sas.com/offices/latinamerica/mexico/technologies/analytics/statistics/index.html
- SPSS, http://es.wikipedia.org/wiki/SPSS
Herramientas de creación de informes o Reporting tools:
Eso es todo, seguiré investigando un poco …




Muy interesante el artículo, Oscar. Muchas gracias.